

出品|搜狐科技
作者|郑松毅
编辑|杨锦
刚刚,由梁文锋担任通讯作者的DeepSeek-R1推理模型研究论文,成功登上国际权威期刊《Nature》封面,再度刷新成就!
与此同时,DeepSeek-R1正式成为全球首个经同行评审的大语言模型。《Nature》高度评价,“经过严格的同行评审流程无疑有助于验证模型的有效性和实用性,几乎所有大模型都没有经过独立同行评审,DeepSeek打破了这一空白。”
《Nature》认为,“当前AI行业存在屡见不鲜的炒作行为,而DeepSeek所做的正是朝着透明度和可重复性迈出的可喜一步。”
今年1月,DeepSeek-R1论文首次公开分享仅靠强化学习,就能激发大模型推理能力的重要研究成果,曾一度被称为“国产AI黑马”,引发美国科技股市暴跌。
Nature介绍,R1模型擅长数学、编程等推理任务,且模型开发成本远低于竞争对手所花费的数千万美元。这一模型还成为全球最受欢迎的开源推理模型,Hugging Face下载量超1090万次。
相较于1月发布的初版DeepSeek-R1论文,本次发表在《Nature》的新版论文,披露了更多模型训练细节,正面回应了有关模型蒸馏的质疑,并首次披露R1训练成本等细节信息。
200万训出R1模型,正面回应模型蒸馏质疑
训练成本方面,R1-Zero和R1都使用了512张H800GPU,训练时长分别是198个小时和80个小时,以《Nature》披露的H800每小时2美元租用价格换算的话,R1的总训练成本为29.4万美元(约合人民币209.5万元)。
数据方面,DeepSeek-R1模型数据集包括数学、编程、STEM、逻辑、通用5个类型的数据。
在R1模型发布之初,曾有传闻质疑该模型使用了OpenAI的模型进行蒸馏。对此,DeepSeek在新论文中给出正面回应,称DeepSeek-V3-Base(R1的基础模型)的预训练数据全部来源于网络,有可能性包括由先进模型(如GPT-4)生成的内容,但DeepSeek并未引入在合成数据集上进行大规模监督蒸馏的“冷却”阶段。
根据论文信息,DeepSeek-V3-Base的数据截止时间为2024年7月,当时并未有先进推理模型发布,进一步降低了DeepSeek从现有推理模型有意蒸馏的可能性。
外界此前对DeepSeek提出的另一质疑在于,厂商在模型训练时有意使用基准测试数据和相关答案对模型进行训练(又称“基础测试数据污染”),相当于开卷训练,有失公平性,导致模型“性能虚高”。
对此,DeepSeek称在R1预训练和后训练阶段均对数据采取了去污策略,确保训练数据和测试评估数据完全不重叠,以反映出模型解决问题的真实能力。
在公开安全基准测试中,DeepSeek-R1在大多数表现上超越Claude-3.7-Sonnet、GPT-o1、GPT-4o等前沿模型。即便作为开源模型,其安全与可靠性仍居大模型市场中上游位置。
在训练过程中,DeepSeek还意外发现了模型的“顿悟时刻”。团队表示,“模型学会了用拟人化的语气进行重新思考,让我们见证了强化学习的力量和魅力。”

在《Nature》的新版论文中,还看到了评审团对DeepSeek提出的建议。包括指出论文关于模型安全的描述过于宽泛、绝对,应该用更严谨的词汇进行安全评估描述;要求DeepSeek对群体相对策略优化算法进行更详尽的描述;以及建议DeepSeek对数据样本进行更相信的披露等。针对这些问题,DeepSeek依次做出解释说明,并在原论文基础上新增多个附录内容。
彰显国产AI实力,推动AI研究走向透明化
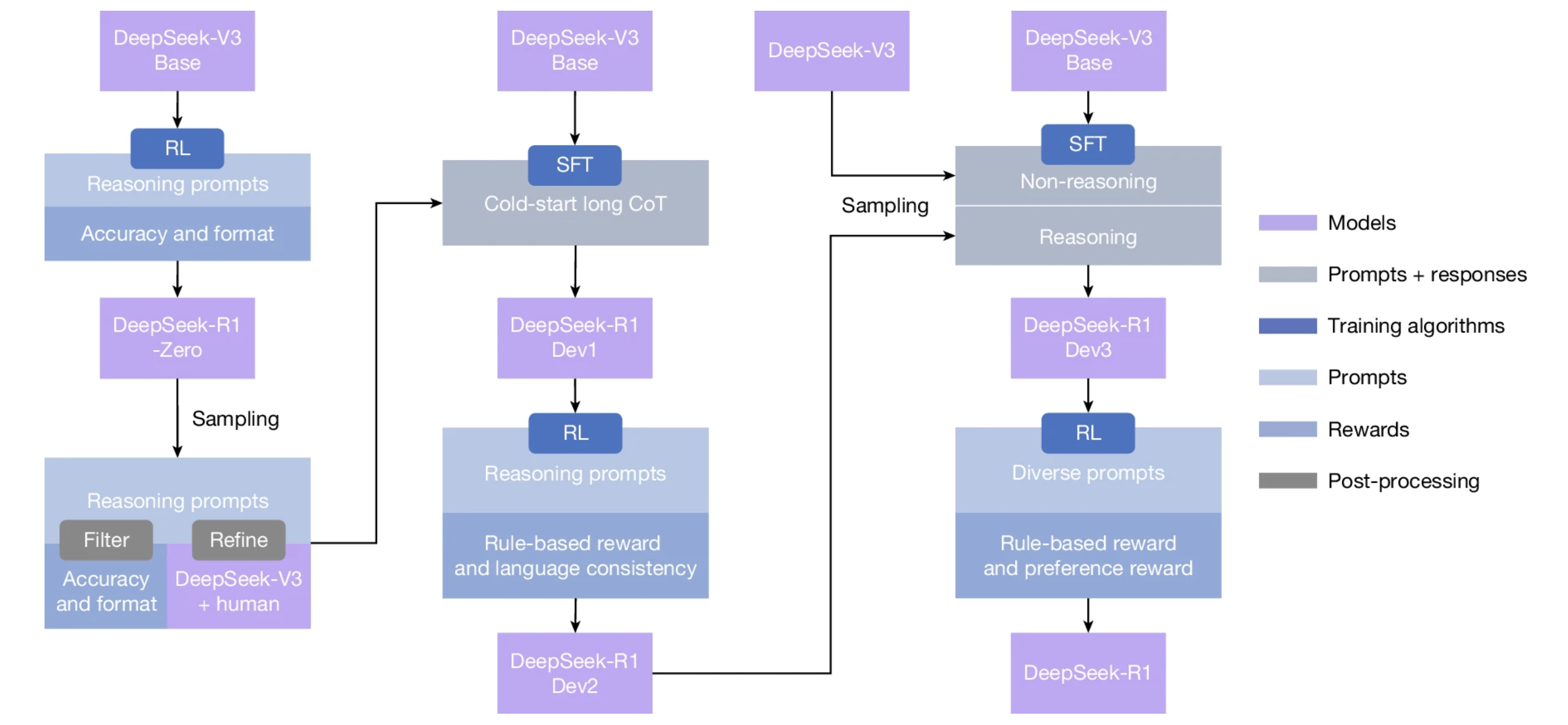
总的来说,DeepSeek-R1(Zero)首次验证了纯强化学习(RL)可使大语言模型(LLM)自主生成复杂推理行为,如反思、验证、长链推理等,无需依赖人工标注数据。
技术实现方面,DeepSeek使用DeepSeek-V3-base作为基础模型,并采用GRPO(Group Relative Policy Optimization)作为强化学习框架来提高模型在任务上的性能表现。
训练阶段,DeepSeek团队对模型先进行推理导向纯强化学习,优化数学、代码等任务的准确性。再通过拒绝采样与 SFT,从模型生成新的多样化推理数据,并重新训练DeepSeek-V3-base模型。过程中仅对模型最终答案的正确性进行奖励,不对推理过程进行约束,最后经新数据微调得到DeepSeek-R1。
从R1实测表现看,其在数学竞赛(AIME 2024)上正确率 79.8%,与 OpenAI 的 o1-1217 持平;在代码竞赛(Codeforces)中达到 2029 分,接近人类专家水平。并在20余项基准任务中表现突出(数学、编程、通用任务能力等),全面领先或逼近海内外顶尖闭源模型。
在创新技术实现模型高性能表现的耀眼成绩下,更让Nature盛赞的,是DeepSeek的开源精神与透明性,以及为整个AI发展生态做出的表率与贡献。
在新版论文最后,DeepSeek也指出当前工作的一些局限性和挑战。包括DeepSeek-R1的结构化输出能力与现有模型相比仍不够理想,并且无法利用搜索引擎、计算器等工具来提升输出性能;在处理其他语言的查询时出现语言混合问题;以及如何优化软件工程进一步提升模型效率等,作为下一阶段DeepSeek攻克的主要方向。
DeepSeek走红之时,梁文锋曾直言“中国不会永远只做追随者”,雄心壮志令人振奋。
如今,DeepSeek 荣登《Nature》封面,这一成果不仅再度向全球彰显了中国 AI 的技术硬实力,更在 AI 基础模型研究领域迈出了关键一步 —— 推动该领域朝着透明化、严谨化的方向继续迈进。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






