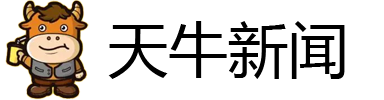


#李鸿其王紫璇回应从恋情到结婚##王紫璇李鸿其想组一个乐队# 2023年,李鸿其的导演首作《爱是一把枪》在威尼斯电影节获得未来之狮奖,也是他首次官宣自己和王紫璇恋情的瞩目时刻。和新浪娱乐@娱理 工作室独家对话时,王紫璇回忆表示,“当时我在剧组拍戏,半夜看直播,那个时刻对我来讲,他太有魅力了。我很难想象任何一个艺人也好,什么人也好,可以在他最高的舞台花了最重要的篇幅公开感谢他的女朋友,当时还不是老婆,他是一个真诚又勇敢的人。”
李鸿其则透露了一件幕后趣事: “《爱是一把枪》的出品人写的是她,但其实全部钱都是我(出)的。原本想给她署名监制的,但一想也不对,还有那么多前辈老师在,我就想那算了,出品人就直接写她吧。”在王紫璇看来,李鸿其是一个底层逻辑非常自信的人,“他不是抱着功利的想法在创作,这样他才能果断拒绝那些机会。我觉得这个东西太可贵了。”
李鸿其也会觉得王紫璇很勇、很有智慧。“我们之前还讨论过说要不要组一个乐队,她弹贝斯,我打鼓,再找一个吉他手就好了。她就真的开始问经纪人有什么音乐节可以去,先从小场子开始…”据了解,王紫璇在浪姐初舞台的表演,编舞老师就是李鸿其的一个高中学长,在《我是全世界最幸福的宝贝》里也有出演,穿着高跟鞋跳舞的戏份令人印象深刻。
看完《我是全世界最幸福的宝贝》首映的观众,会觉得李鸿其把王紫璇拍得太美了。作为该片的摄影指导、掌镜者,李鸿其向@娱理 透露,有学习研究泰伦斯·马力克等大师导演是怎么拍人的,还参考了《两天一夜》的手持摄影。片中多次利用了自然光/阳光来打造氛围感,王紫璇基本是素颜出镜…更多内容,请看#娱理独家#↓








 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






